
How can we truly identify the leader in the race for artificial intelligence? Tech giants such as OpenAI, Google, and Anthropic compete with hyperbole to tout the performance of their latest models. In doing so, they create a media fog that is difficult for technical decision-makers and companies to penetrate. This situation has created a need for rigorous objectivity, delivered by independent observers capable of separating the signal from the noise.
This is precisely the role played by Artificial Analysis, the go-to platform for anyone seeking to understand where the real performance lies, far from carefully choreographed demonstrations. By focusing on tangible metrics and complex intelligence tests, this resource provides an indispensable compass in a rapidly evolving market.
The necessary objectivity of Artificial Analysis
The reliability of the promises made by the dominant players in AI has been put to the test on several occasions. When a company announces a new “revolutionary” model, it has every interest in highlighting its strengths, often by testing ideal use cases that do not necessarily reflect the operational reality of a business. This trend has created a gap between laboratory performance and real-world performance, making technology investment choices increasingly risky.
This is where the intervention of an independent third party becomes crucial. Platforms such as Artificial Analysis do not depend on the marketing budgets of AI vendors. Their reputation is based on the transparency and reproducibility of their tests. By eliminating commercial bias, they allow models to be compared on the basis of common, standardized criteria. For a company, this means the difference between choosing a model based on a dazzling demonstration and choosing a model that effectively solves a specific problem at a reasonable cost. Objectivity is no longer an academic luxury; it is an economic necessity.
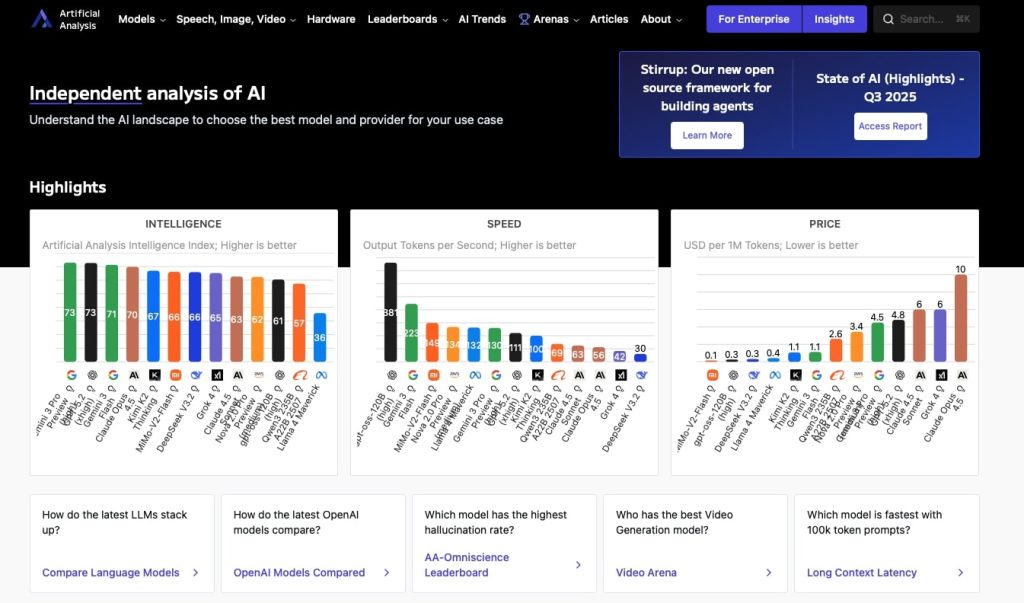
The criteria that make the difference: Speed and cost, the language of business
To properly evaluate an AI model, it is tempting to focus solely on its ability to answer general knowledge questions or solve complex mathematical problems. However, in a business context, two practical criteria often take precedence over pure academic intelligence: execution speed and cost per token. These two factors determine the economic and technical viability of large-scale integration.
Processing speed (tokens per second)
Speed, measured in tokens per second (tokens/sec), directly influences the user experience and processing capacity. A model that takes several seconds to generate a response is unsuitable for real-time applications, such as customer support chatbots or interactive coding assistants. Artificial Analysis highlights significant disparities between models. For example, a model such as Gemini 3 Flash can offer higher throughput than heavier models such as Claude Opus, which can be decisive for applications requiring minimal latency. Speed also reduces infrastructure costs by processing more queries with the same resources.
The price factor (cost per million tokens)
Cost is arguably the biggest barrier to widespread AI adoption. Prices vary considerably from one provider to another and even between different versions of the same model. An “intelligent” but exorbitantly priced model can quickly eat into a product’s margin. Artificial Analysis provides accurate data on token input and output prices, allowing developers to calculate the total cost of ownership. It is thanks to this transparency that optimization strategies, such as using lighter models for simple tasks, can be implemented.
The Artificial Analysis Intelligence Index v3.0 Leaderboard
At the heart of the analysis lies Artificial Analysis’ Intelligence Index v3.0. This dashboard doesn’t just compare models on a single dimension; it evaluates them across a broad spectrum of ten distinct assessments. This holistic approach ensures that the ranking reflects versatile and robust intelligence capable of adapting to a variety of contexts.
The 10 key evaluations
V3.0 incorporates cutting-edge benchmarks covering general knowledge (MMLU-Pro), high-level scientific reasoning (GPQA Diamond), mathematical problem solving (AIME 2025), and code generation (LiveCodeBench, SciCode). It also includes reasoning tests on long contexts (AA-LCR, Humanity’s Last Exam) and specific technical tasks (Terminal-Bench Hard, 𝜏²-Bench Telecom). This diversity of tests prevents models from “cheating” by over-learning specific domains and ensures that the current leader is truly at the cutting edge of technology.
Who dominates the current rankings?
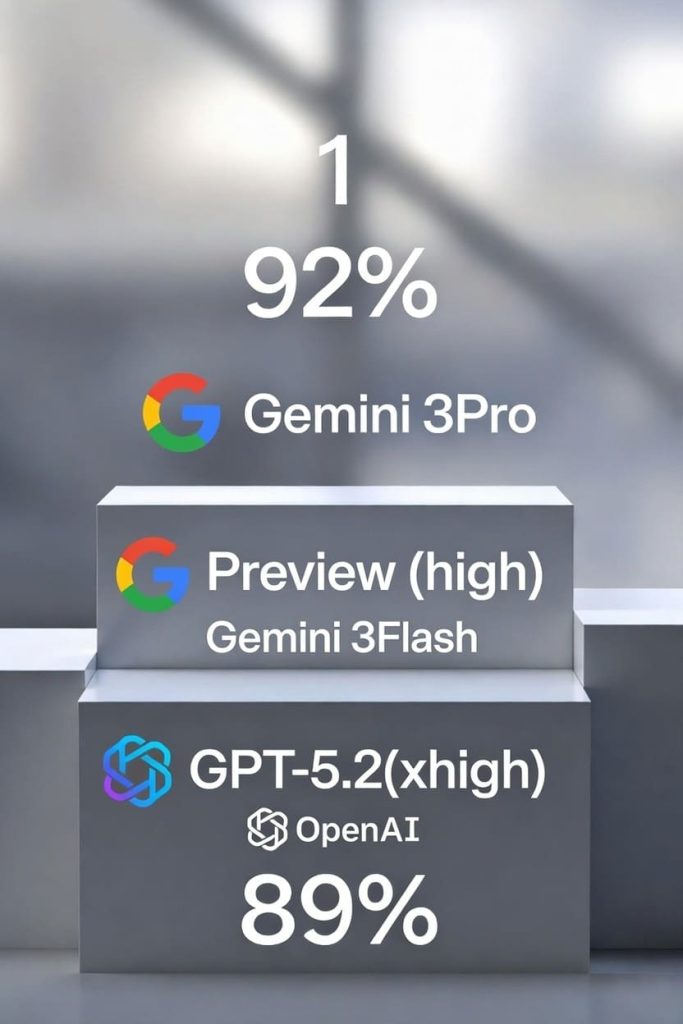
Analyzing the most recent data, a clear trend emerges. Competition is fierce, but certain names consistently come out on top. According to the latest Intelligence Index results, OpenAI’s GPT-5.2 (xhigh) model currently seems to be in the lead, followed closely by Google’s Gemini 3 Pro Preview (high) and Anthropic’s Claude Opus 4.5. These three models are vying for first place with very close scores, demonstrating that the technological advantage is measured in fractions of points. Other models such as GLM-4.7 or Kimi K2Thinking offer competitive performance, often with a better price-performance ratio, making them relevant for specific use cases.
Focus on specialists: Coding and Long Context Reasoning
While the overall ranking provides an overview, the subcategories reveal the true strengths of the models. For companies with specific needs, such as software development or large document analysis, these specialized rankings are even more relevant than the overall ranking.
The code duel: LiveCodeBench
The LiveCodeBench benchmark is the gold standard for evaluating a model’s ability to write functional, correct, and efficient code. Here, the hierarchy may differ from the overall hierarchy. The results often show that models trained specifically for coding, or those that benefit from extensive optimization in this area, have the advantage. Models from the Gemini family (Pro Preview and Flash) as well as GLM-4.7 frequently stand out in this area, sometimes outperforming more general-purpose models on concrete programming tasks.
The challenge of long context: AA-LCR
The analysis of very long documents (Long Context Reasoning) is a major challenge for legal analysis, document research, and report synthesis. The AA-LCR benchmark tests the model’s ability to maintain consistency and extract relevant information from thousands of tokens. Models such as GPT-5.1 (high) and Claude Opus 4.5 traditionally excel in this category, offering superior contextual memory that is essential for complex enterprise applications.
Performance and cost comparison table
To visualize the trade-offs between performance and cost, Artificial Analysis allows you to cross-reference this data. The following table is a fictional but representative summary of the data found on the platform to illustrate how decisions are made (prices and speeds are estimates based on current trends to illustrate the analysis method).
| Model | Score Index (approx.) | Speed (Tok/sec) | Cost (Input/Output $/1M) |
|---|---|---|---|
| GPT-5.2 (xhigh) | 88.5 | ~45 | $15.00 / $60.00 |
| Gemini 3 Pro Preview | 87.9 | ~55 | $12.50 / $50.00 |
| Claude Opus 4.5 | 87.2 | ~30 | $15.00 / $75.00 |
| DeepSeek V3.2 | 82.0 | ~60 | $2.00 / $8.00 |
Open Weights vs. Proprietary: The Underlying Debate
An important dimension analyzed by Artificial Analysis is the distinction between proprietary (closed) models and open weights models. This distinction is vital for many companies concerned about their digital sovereignty and long-term costs.
The Appeal of Open Source
Models such as DeepSeek V3.2 or GLM-4.7 allow companies to deploy AI on their own servers (on-premise) or on private clouds. This provides complete control over data, which is essential for regulated industries such as healthcare or finance. In addition, the absence of recurring per-token fees can make these models extremely economical for massive usage volumes, even if the initial infrastructure is more expensive.
The Proprietary Performance Standard
On the other hand, proprietary models such as those from OpenAI or Google continue to dominate the overall Intelligence Index rankings. They have the huge advantage of being hosted and maintained by their creators, offering ease of integration and constant updates without any technical effort on the part of the customer. For startups and SMEs that want to focus on their end product without managing complex AI infrastructure, the proprietary route is often the fastest, although potentially more expensive in the long run.
Conclusion: The compass for the future of AI
In the frantic race for artificial intelligence, the ability to succeed is measured not by promises, but by tangible results, controlled costs, and proven reliability. Artificial Analysis has established itself as the impartial arbiter of this competition, offering a clear and factual view of who is really leading the way. Whether through its Intelligence Index v3.0, its speed and price analyses, or its specialized rankings in coding and long-context reasoning, the platform provides the tools needed to navigate this complex landscape. For businesses and developers, the message is clear: don’t trust marketing, trust data. Using these independent analyses is the only guarantee of making the technological choices that will shape your future.

Tanguy is a key figure in the team, responsible for in-depth analysis of technological trends and their practical application in modern business. One of his specialities are the blockchains.

